Title: Object Class Recognition by Unsupervised Scale-Invariant Learning
Author: R. Fergus1 P. Perona2 A. Zisserman1
Abstract:
We present a method to learn and recognize object class
models from unlabeled and unsegmented cluttered scenes
in a scale invariant manner. Objects are modeled as flexible
constellations of parts. A probabilistic representation is
used for all aspects of the object: shape, appearance, occlusion
and relative scale. An entropy-based feature detector
is used to select regions and their scale within the image. In
learning the parameters of the scale-invariant object model
are estimated. This is done using expectation-maximization
in a maximum-likelihood setting. In recognition, this model
is used in a Bayesian manner to classify images. The flexible
nature of the model is demonstrated by excellent results
over a range of datasets including geometrically constrained
classes (e.g. faces, cars) and flexible objects (such
as animals).
Full text:
link
Tuesday, October 31, 2006
Monday, October 30, 2006
Title: Learning Dynamic Maps of Temporal Gene Regulation
Title: Learning Dynamic Maps of Temporal Gene Regulation
Speaker: Jason Ernst, CMU [Link]
Venue: NSH 1507
Date: October 30
Time: 12:00 noon
For schedules, links to papers et al, please see the web page: Link
Abstract:
Time series microarray gene expression experiments have become a widely used experimental technique to study the dynamic biological responses of organisms to a variety of stimuli. The data from these experiments are often clustered to reveal significant temporal expression patterns. These observed temporal expression patterns are largely a result of a dynamic network of protein-DNA interactions that allows the specific regulation of genes needed for the response. We have developed a novel computational method that uses an Input-Output Hidden Markov Model to model these regulatory networks while taking into account their dynamic nature. Our method works by identifying bifurcation points, places in the time series where the expression of a subset of genes diverges from the rest of the genes. These points are annotated with the transcription factors regulating these transitions resulting in a unified dynamic map. Applying our method to study yeast response to stress we derive dynamic maps that are able to recover many of the known aspects of these responses. Additionally the method has made new predictions that have been experimentally validated.
Speaker: Jason Ernst, CMU [Link]
Venue: NSH 1507
Date: October 30
Time: 12:00 noon
For schedules, links to papers et al, please see the web page: Link
Abstract:
Time series microarray gene expression experiments have become a widely used experimental technique to study the dynamic biological responses of organisms to a variety of stimuli. The data from these experiments are often clustered to reveal significant temporal expression patterns. These observed temporal expression patterns are largely a result of a dynamic network of protein-DNA interactions that allows the specific regulation of genes needed for the response. We have developed a novel computational method that uses an Input-Output Hidden Markov Model to model these regulatory networks while taking into account their dynamic nature. Our method works by identifying bifurcation points, places in the time series where the expression of a subset of genes diverges from the rest of the genes. These points are annotated with the transcription factors regulating these transitions resulting in a unified dynamic map. Applying our method to study yeast response to stress we derive dynamic maps that are able to recover many of the known aspects of these responses. Additionally the method has made new predictions that have been experimentally validated.
Sunday, October 29, 2006
Batch Mode Active Learning
When: Friday October 27, at 10amWhere: Intel Research (4th floor CIC)
Speaker: Rong Jin (MSU)Title: Batch Mode Active Learning
Abstract:
The goal of active learning is to select the most informativeexamples for manual labeling. Most of the previous studies in activelearning have focused on selecting a single unlabeled example in eachiteration. This is inefficient since the classification model has to beretrained for every labeled example that is solicited. In this paper, wepresent a framework for "batch mode active learning" that applies theFisher information matrix to select a number of informative examplessimultaneously. The key computational challenge is how to efficientlyidentify the subset of unlabeled examples that can result in thelargest reduction in the classification uncertainty. In this talk, Iwill discuss two different computational approaches: one is based onthe approximated semi-definitive programming technique and the other isbased on the property of submodular functions. Empirical studies showthe promising results of the proposed approaches for batch mode activelearning in comparison to the state-of-the-art active learning methods.
Bio:
Dr. Rong Jin is an assistant Prof. of the Computer and Science
Engineering Dept. of Michigan State University since 2003. He is working
in the areas of statistical machine learning and its application to
information retrieval. In the past, Dr. Jin has worked on a variety
of machine learning algorithms, and has presented efficient and
robust algorithms for conditional exponential models, support vector
machine, and boosting. In addition, he has extensive experience
with the application of machine learning algorithms to information
retrieval, including retrieval models, collaborative filtering, cross
lingual information retrieval, document clustering, and video/image
retrieval. In the past, he has published over sixty conference and
journal articles on the related topics. Dr. Jin holds a B.A. in
Engineering from Tianjin University, an M.S. in Physics from Beijing
University, and an M.S. and Ph.D. in the area of language technologies
from Carnegie Mellon University.
Speaker: Rong Jin (MSU)Title: Batch Mode Active Learning
Abstract:
The goal of active learning is to select the most informativeexamples for manual labeling. Most of the previous studies in activelearning have focused on selecting a single unlabeled example in eachiteration. This is inefficient since the classification model has to beretrained for every labeled example that is solicited. In this paper, wepresent a framework for "batch mode active learning" that applies theFisher information matrix to select a number of informative examplessimultaneously. The key computational challenge is how to efficientlyidentify the subset of unlabeled examples that can result in thelargest reduction in the classification uncertainty. In this talk, Iwill discuss two different computational approaches: one is based onthe approximated semi-definitive programming technique and the other isbased on the property of submodular functions. Empirical studies showthe promising results of the proposed approaches for batch mode activelearning in comparison to the state-of-the-art active learning methods.
Bio:
Dr. Rong Jin is an assistant Prof. of the Computer and Science
Engineering Dept. of Michigan State University since 2003. He is working
in the areas of statistical machine learning and its application to
information retrieval. In the past, Dr. Jin has worked on a variety
of machine learning algorithms, and has presented efficient and
robust algorithms for conditional exponential models, support vector
machine, and boosting. In addition, he has extensive experience
with the application of machine learning algorithms to information
retrieval, including retrieval models, collaborative filtering, cross
lingual information retrieval, document clustering, and video/image
retrieval. In the past, he has published over sixty conference and
journal articles on the related topics. Dr. Jin holds a B.A. in
Engineering from Tianjin University, an M.S. in Physics from Beijing
University, and an M.S. and Ph.D. in the area of language technologies
from Carnegie Mellon University.
Thursday, October 26, 2006
Lab meeitng 27 Oct., 2006 (Bright): Better Motion Prediction for People-tracking
Authors: Allison Bruce and Geoffrey Gordon
From: ICRA 2004
Abstract:An important building block for intelligent mobile
robots is the ability to track people moving around in the environment.
Algorithms for person-tracking often incorporate motion
models, which can improve tracking accuracy by predicting how
people will move. More accurate motion models produce better
tracking because they allow us to average together multiple
predictions of the person’s location rather than depending
entirely on the most recent observation. Many implemented
systems, however, use simple conservative motion models such
as Brownian motion (in which the person’s direction of motion
is independent on each time step). We present an improved
motion model based on the intuition that people tend to follow
efficient trajectories through their environments rather than
random paths. Our motion model learns common destinations
within the environment by clustering training examples of actual
trajectories, then uses a path planner to predict how a person
would move along routes from his or her present location
to these destinations. We have integrated this motion model
into a particle-filter-based person-tracker, and we demonstrate
experimentally that our new motion model performs significantly
better than simpler models, especially in situations in which there
are extended periods of occlusion during tracking.
Link
From: ICRA 2004
Abstract:An important building block for intelligent mobile
robots is the ability to track people moving around in the environment.
Algorithms for person-tracking often incorporate motion
models, which can improve tracking accuracy by predicting how
people will move. More accurate motion models produce better
tracking because they allow us to average together multiple
predictions of the person’s location rather than depending
entirely on the most recent observation. Many implemented
systems, however, use simple conservative motion models such
as Brownian motion (in which the person’s direction of motion
is independent on each time step). We present an improved
motion model based on the intuition that people tend to follow
efficient trajectories through their environments rather than
random paths. Our motion model learns common destinations
within the environment by clustering training examples of actual
trajectories, then uses a path planner to predict how a person
would move along routes from his or her present location
to these destinations. We have integrated this motion model
into a particle-filter-based person-tracker, and we demonstrate
experimentally that our new motion model performs significantly
better than simpler models, especially in situations in which there
are extended periods of occlusion during tracking.
Link
[MIT CSAIL] Navigating and Reconstructing the World's Photographs
Title : Navigating and Reconstructing the World's Photographs
Speaker : Steven Seitz , University of Washington
Abstract :
There are billions of photographs on the Internet. Virtually all of the world's significant sites have been photographed under many different conditions, both from the ground and from the air. For example, a Google image search for "Notre Dame" returns half a million images, showing the cathedral from almost every conceivable viewing position and angle, different times of day and night, and changes in season, weather, and decade. In many ways, this is the dream data set for computer vision and graphics research.
Motivated by the availability of such rich data, we are exploring matching, reconstruction, and visualization algorithms that can work with very large, unorganized, and uncalibrated images sets, such as those found on the Internet. In this talk, I'll describe "Photo Tourism," (now being commercialized by Microsoft as "Photosynth"), an approach that creates immersive 3D experiences of scenes by reconstructing photographs on the Internet. I'll also describe work on multi-view stereo that reconstructs accurate 3D models from large collections of input views.
This is joint work with Noah Snavely, Rick Szeliski, Michael Goesele, Brian Curless, and Hugues Hoppe.
Bio :
Steven Seitz is Short-Dooley Associate Professor in the Department of Computer Science and Engineering at the University of Washington. He received his B.A. in computer science and mathematics at the University of California, Berkeley in 1991 and his Ph.D. in computer sciences at the University of Wisconsin, Madison in 1997. Following his doctoral work, he spent one year visiting the Vision Technology Group at Microsoft Research, and subsequently two years as an Assistant Professor in the Robotics Institute at Carnegie Mellon University. He joined the faculty at the University of Washington in July 2000. He was twice awarded the David Marr Prize for the best paper at the International Conference of Computer Vision, and has received an NSF Career Award, an ONR Young Investigator Award, and an Alfred P. Sloan Fellowship. Professor Seitz is interested in problems in computer vision and computer graphics. His current research focuses on capturing the structure, appearance, and behavior of the real world from digital imagery.
Speaker : Steven Seitz , University of Washington
Abstract :
There are billions of photographs on the Internet. Virtually all of the world's significant sites have been photographed under many different conditions, both from the ground and from the air. For example, a Google image search for "Notre Dame" returns half a million images, showing the cathedral from almost every conceivable viewing position and angle, different times of day and night, and changes in season, weather, and decade. In many ways, this is the dream data set for computer vision and graphics research.
Motivated by the availability of such rich data, we are exploring matching, reconstruction, and visualization algorithms that can work with very large, unorganized, and uncalibrated images sets, such as those found on the Internet. In this talk, I'll describe "Photo Tourism," (now being commercialized by Microsoft as "Photosynth"), an approach that creates immersive 3D experiences of scenes by reconstructing photographs on the Internet. I'll also describe work on multi-view stereo that reconstructs accurate 3D models from large collections of input views.
This is joint work with Noah Snavely, Rick Szeliski, Michael Goesele, Brian Curless, and Hugues Hoppe.
Bio :
Steven Seitz is Short-Dooley Associate Professor in the Department of Computer Science and Engineering at the University of Washington. He received his B.A. in computer science and mathematics at the University of California, Berkeley in 1991 and his Ph.D. in computer sciences at the University of Wisconsin, Madison in 1997. Following his doctoral work, he spent one year visiting the Vision Technology Group at Microsoft Research, and subsequently two years as an Assistant Professor in the Robotics Institute at Carnegie Mellon University. He joined the faculty at the University of Washington in July 2000. He was twice awarded the David Marr Prize for the best paper at the International Conference of Computer Vision, and has received an NSF Career Award, an ONR Young Investigator Award, and an Alfred P. Sloan Fellowship. Professor Seitz is interested in problems in computer vision and computer graphics. His current research focuses on capturing the structure, appearance, and behavior of the real world from digital imagery.
[CMU Intelligence Seminar] Robust Autonomous Color Learning on a Mobile Robot
Title : Robust Autonomous Color Learning on a Mobile Robot
Abstract :
The scientific community is slowly but surely working towards the creation of fully autonomous mobile robots capable of interacting with the proverbial real world. To operate in the real world, autonomous robots rely on their sensory information, but the ability to accurately sense the complex world is still missing. Visual input, in the form of color images from a camera, should be an excellent and rich source of such information, considering the significant amount of progress made in machine vision. But color, and images in general, have been used sparingly on mobile robots, where people have mostly focused their attention on other sensors such as tactile sensors, sonar and laser.
This talk presents the challenges raised and solutions introduced in our efforts to create a robust, color-based visual system for the Sony Aibo robot. We enable the robot to learn its color map autonomously and demonstrate a degree of illumination invariance under changing lighting conditions. Our contributions are fully implemented and operate in real time within the limited processing resources available onboard the robot. The system has been deployed in periodic robot soccer competitions, enabling teams of four Aibo robots to play soccer as a part of the international RoboCup initiative.
Bio :
Dr. Peter Stone is an Alfred P. Sloan Research Fellow and Assistant Professor in the Department of Computer Sciences at the University of Texas at Austin. He received his Ph.D in Computer Science in 1998 from Carnegie Mellon University. From 1999 to 2002 he was a Senior Technical Staff Member in the Artificial Intelligence Principles Research Department at AT&T Labs - Research. Peter's research interests include machine learning, multiagent systems, robotics, and e-commerce. In 2003, he won a CAREER award from the National Science Foundation for his research on learning agents in dynamic, collaborative, and adversarial multiagent environments. In 2004, he was named an ONR Young Investigator for his research on machine learning on physical robots. Most recently, he was awarded the prestigious IJCAI 2007 Computers and Thought award.
Abstract :
The scientific community is slowly but surely working towards the creation of fully autonomous mobile robots capable of interacting with the proverbial real world. To operate in the real world, autonomous robots rely on their sensory information, but the ability to accurately sense the complex world is still missing. Visual input, in the form of color images from a camera, should be an excellent and rich source of such information, considering the significant amount of progress made in machine vision. But color, and images in general, have been used sparingly on mobile robots, where people have mostly focused their attention on other sensors such as tactile sensors, sonar and laser.
This talk presents the challenges raised and solutions introduced in our efforts to create a robust, color-based visual system for the Sony Aibo robot. We enable the robot to learn its color map autonomously and demonstrate a degree of illumination invariance under changing lighting conditions. Our contributions are fully implemented and operate in real time within the limited processing resources available onboard the robot. The system has been deployed in periodic robot soccer competitions, enabling teams of four Aibo robots to play soccer as a part of the international RoboCup initiative.
Bio :
Dr. Peter Stone is an Alfred P. Sloan Research Fellow and Assistant Professor in the Department of Computer Sciences at the University of Texas at Austin. He received his Ph.D in Computer Science in 1998 from Carnegie Mellon University. From 1999 to 2002 he was a Senior Technical Staff Member in the Artificial Intelligence Principles Research Department at AT&T Labs - Research. Peter's research interests include machine learning, multiagent systems, robotics, and e-commerce. In 2003, he won a CAREER award from the National Science Foundation for his research on learning agents in dynamic, collaborative, and adversarial multiagent environments. In 2004, he was named an ONR Young Investigator for his research on machine learning on physical robots. Most recently, he was awarded the prestigious IJCAI 2007 Computers and Thought award.
[FRC seminar] Dynamic Tire-Terrain Models for Obstacle Detection
Speaker:
Dean Anderson
Ph.D. Candidate
Robotics Institute
Abstract:
What is an obstacle? In mobile robots, this is a question implicitly addressed by a perception system, but rarely directly studied itself.
As robots achieve higher speeds and venture into rougher terrain, dynamic effects become significant and cost metrics based on quasi-static analysis and heuristics perform sub-optimally.
In this talk, we present a calibrated, fully-dynamic deformable tire model for terrain evaluation. The tire model is based on penetrating volumes and includes both rolling and slipping friction forces. We will also discuss an experimental platform used to calibrate the model and insights gained in studying the effects of vehicle speed, obstacle height and slope on the "lethality" of an obstacle. Lastly, we propose a metric of terrain traversability based on our force model, and compare it to previous perception algorithms.
Speaker Bio:
Dean Anderson is a fourth-year Ph.D. student working with Alonzo Kelly. His research interests include sensors and perception algorithms for outdoor mobile robots, as well as dynamic vehicle modeling for perception and planning purposes.
Dean Anderson
Ph.D. Candidate
Robotics Institute
Abstract:
What is an obstacle? In mobile robots, this is a question implicitly addressed by a perception system, but rarely directly studied itself.
As robots achieve higher speeds and venture into rougher terrain, dynamic effects become significant and cost metrics based on quasi-static analysis and heuristics perform sub-optimally.
In this talk, we present a calibrated, fully-dynamic deformable tire model for terrain evaluation. The tire model is based on penetrating volumes and includes both rolling and slipping friction forces. We will also discuss an experimental platform used to calibrate the model and insights gained in studying the effects of vehicle speed, obstacle height and slope on the "lethality" of an obstacle. Lastly, we propose a metric of terrain traversability based on our force model, and compare it to previous perception algorithms.
Speaker Bio:
Dean Anderson is a fourth-year Ph.D. student working with Alonzo Kelly. His research interests include sensors and perception algorithms for outdoor mobile robots, as well as dynamic vehicle modeling for perception and planning purposes.
[CMU Intelligence Seminar]] Improving Systems Management Policies Using Hybrid Reinforcement Learning
Other information of Intelligence Seminar [link]
Topic: Improving Systems Management Policies Using Hybrid Reinforcement Learning
Speaker: Gerry Tesauro (IBM Watson Research)
Abstract:
Reinforcement Learning (RL) provides a promising new approach to systems
performance management that differs radically from standard
queuing-theoretic approaches making use of explicit system performance
models. In principle, RL can automatically learn high-quality management
policies without explicit performance models or traffic models, and with
little or no built-in system specific knowledge. Previously we showed
that online RL can learn to make high-quality server allocation
decisions in a multi-application prototype Data Center scenario. The
present work shows how to combine the strengths of both RL and queuing
models in a hybrid approach, in which RL trains offline on data
collected while a queuing model policy controls the system. By training
offline we avoid suffering potentially poor performance in live online
training. Our latest results show that, in both open-loop and
closed-loop traffic, hybrid RL training can achieve significant
performance improvements over a variety of initial model-based policies.
We also give several interesting insights as to how RL, as expected, can
deal effectively with both transients and switching delays, which lie
outside the scope of traditional steady-state queuing theory.
Speaker Bio:
Gerry Tesauro received a PhD in theoretical physics from Princeton
University in 1986, and owes his subsequent conversion to machine
learning research in no small part to the first Connectionist Models
Summer School, held at Carnegie Mellon in 1986. Since then he has worked
on a variety of ML applications, including computer virus recognition,
intelligent e-commerce agents, and most notoriously, TD-Gammon, a
self-teaching program that learned to play backgammon at human world
championship level. He has also been heavily involved for many years in
the annual NIPS conference, and was NIPS Program Chair in 1993 and
General Chair in 1994. He is currently interested in applying the latest
and greatest ML approaches to a huge emerging application domain of
self-managing computing systems, where he foresees great opportunities
for improvements over current state-of-the-art approaches.
Topic: Improving Systems Management Policies Using Hybrid Reinforcement Learning
Speaker: Gerry Tesauro (IBM Watson Research)
Abstract:
Reinforcement Learning (RL) provides a promising new approach to systems
performance management that differs radically from standard
queuing-theoretic approaches making use of explicit system performance
models. In principle, RL can automatically learn high-quality management
policies without explicit performance models or traffic models, and with
little or no built-in system specific knowledge. Previously we showed
that online RL can learn to make high-quality server allocation
decisions in a multi-application prototype Data Center scenario. The
present work shows how to combine the strengths of both RL and queuing
models in a hybrid approach, in which RL trains offline on data
collected while a queuing model policy controls the system. By training
offline we avoid suffering potentially poor performance in live online
training. Our latest results show that, in both open-loop and
closed-loop traffic, hybrid RL training can achieve significant
performance improvements over a variety of initial model-based policies.
We also give several interesting insights as to how RL, as expected, can
deal effectively with both transients and switching delays, which lie
outside the scope of traditional steady-state queuing theory.
Speaker Bio:
Gerry Tesauro received a PhD in theoretical physics from Princeton
University in 1986, and owes his subsequent conversion to machine
learning research in no small part to the first Connectionist Models
Summer School, held at Carnegie Mellon in 1986. Since then he has worked
on a variety of ML applications, including computer virus recognition,
intelligent e-commerce agents, and most notoriously, TD-Gammon, a
self-teaching program that learned to play backgammon at human world
championship level. He has also been heavily involved for many years in
the annual NIPS conference, and was NIPS Program Chair in 1993 and
General Chair in 1994. He is currently interested in applying the latest
and greatest ML approaches to a huge emerging application domain of
self-managing computing systems, where he foresees great opportunities
for improvements over current state-of-the-art approaches.
Tuesday, October 24, 2006
Inference in Large-Scale Graphical Models and its application to SFM, SAM, and SLAM
Inference in Large-Scale Graphical Models and its application to SFM, SAM, and SLAM
Frank Dellaert, Georgia Tech.
Intelligence Seminar at School of Computer Science at Carnegie Mellon University
Abstract:
Simultaneous Localization and Mapping (SLAM), Smoothing and Mapping (SAM), and Structure from Motion (SFM) are important and closely related problems in robotics and vision. Not surprisingly, there is a large literature describing solutions to each problem, and more and more connections are established between the two fields. At the same time, robotics and vision researchers alike are becoming increasingly familiar with the power of graphical models as a language in which to represent inference problems. In this talk I will show how SFM, SAM, and SLAM can be posed in terms of this graphical model language, and how inference in them can be explained in a purely graphical manner via the concept of variable elimination. I will then present a new way of looking at inference that is equivalent to the junction tree algorithm yet is — in my view — much more insightful. I will also show that, when applied to linear(ized) Gaussian problems, the algorithm yields the familiar QR and Cholesky factorization algorithms, and that this connection with linear algebra leads to strategies for very fast inference in arbitrary graphs. I will conclude by showing some published and preliminary work that exploits this connection to the fullest.
Links:
[Author info]
Frank Dellaert, Georgia Tech.
Intelligence Seminar at School of Computer Science at Carnegie Mellon University
Abstract:
Simultaneous Localization and Mapping (SLAM), Smoothing and Mapping (SAM), and Structure from Motion (SFM) are important and closely related problems in robotics and vision. Not surprisingly, there is a large literature describing solutions to each problem, and more and more connections are established between the two fields. At the same time, robotics and vision researchers alike are becoming increasingly familiar with the power of graphical models as a language in which to represent inference problems. In this talk I will show how SFM, SAM, and SLAM can be posed in terms of this graphical model language, and how inference in them can be explained in a purely graphical manner via the concept of variable elimination. I will then present a new way of looking at inference that is equivalent to the junction tree algorithm yet is — in my view — much more insightful. I will also show that, when applied to linear(ized) Gaussian problems, the algorithm yields the familiar QR and Cholesky factorization algorithms, and that this connection with linear algebra leads to strategies for very fast inference in arbitrary graphs. I will conclude by showing some published and preliminary work that exploits this connection to the fullest.
Links:
[Author info]
Lab meeitng 27 Oct., 2006 (Eric): Rapid Shape Acquisition Using Color Structured Light and Multi-pass Dynamic Programming
Authors:Li Zhang, Brian Curless, and Steven M. Seitz
From:In Proceedings of the 1st International Symposium on 3D Data Processing, Visualization, and Transmission (3DPVT) 2002
Abstract:This paper presents a color structured light technique forrecovering object shape from one or more images. The techniqueworks by projecting a pattern of stripes of alternatingcolors and matching the projected color transitions with observededges in the image. The correspondence problem issolved using a novel, multi-pass dynamic programming algorithmthat eliminates global smoothness assumptions andstrict ordering constraints present in previous formulations.The resulting approach is suitable for generating both highspeedscans of moving objects when projecting a single stripepattern and high-resolution scans of static scenes using ashort sequence of time-shifted stripe patterns. In the lattercase, spacetime analysis is used at each sensor pixel to obtaininter-frame depth localization. Results are demonstratedfor a variety of complex scenes.
From:In Proceedings of the 1st International Symposium on 3D Data Processing, Visualization, and Transmission (3DPVT) 2002
Abstract:This paper presents a color structured light technique forrecovering object shape from one or more images. The techniqueworks by projecting a pattern of stripes of alternatingcolors and matching the projected color transitions with observededges in the image. The correspondence problem issolved using a novel, multi-pass dynamic programming algorithmthat eliminates global smoothness assumptions andstrict ordering constraints present in previous formulations.The resulting approach is suitable for generating both highspeedscans of moving objects when projecting a single stripepattern and high-resolution scans of static scenes using ashort sequence of time-shifted stripe patterns. In the lattercase, spacetime analysis is used at each sensor pixel to obtaininter-frame depth localization. Results are demonstratedfor a variety of complex scenes.
[Link]
[My talk] The Identity Management Kalman Filter (IMKF)
Title: The Identity Management Kalman Filter (IMKF)
Authors: Brad Schumitsch, Sebastian Thrun, Leonidas Guibas, Kunle Olukotun
Robotics: Science and Systems II (RSS 2006)
August 16-19, 2006
University of Pennsylvania
Philadelphia, Pennsylvania
Abstract: Tracking posteriors estimates for problems with data association uncertainty is one of the big open problems in the literature on filtering and tracking. This paper presents a new filter for online tracking of many individual objects with data association ambiguities. It tightly integrates the continuous aspects of the problem -- locating the objects -- with the discrete aspects -- the data association ambiguity. The key innovation is a probabilistic information matrix that efficiently does identity management, that is, it links entities with internal tracks of the filter, enabling it to maintain a full posterior over the system amid data association uncertainties. The filter scales quadratically in complexity, just like a conventional Kalman filter. We derive the algorithm formally and present large-scale results.
PDF:
http://www.roboticsproceedings.org/rss02/p29.pdf
Authors: Brad Schumitsch, Sebastian Thrun, Leonidas Guibas, Kunle Olukotun
Robotics: Science and Systems II (RSS 2006)
August 16-19, 2006
University of Pennsylvania
Philadelphia, Pennsylvania
Abstract: Tracking posteriors estimates for problems with data association uncertainty is one of the big open problems in the literature on filtering and tracking. This paper presents a new filter for online tracking of many individual objects with data association ambiguities. It tightly integrates the continuous aspects of the problem -- locating the objects -- with the discrete aspects -- the data association ambiguity. The key innovation is a probabilistic information matrix that efficiently does identity management, that is, it links entities with internal tracks of the filter, enabling it to maintain a full posterior over the system amid data association uncertainties. The filter scales quadratically in complexity, just like a conventional Kalman filter. We derive the algorithm formally and present large-scale results.
PDF:
http://www.roboticsproceedings.org/rss02/p29.pdf
Friday, October 20, 2006
News: Robot swarm works together to shift heavy objects
* 18:47 17 October 2006
* NewScientist.com news service
* Tom Simonite
A "swarm" of simple-minded robots that teams up to move an object too heavy for them to manage individually has been demonstrated by robotics researchers.
The robots cannot communicate and must act only on what they can see around them. They follow simple rules to fulfil their task - mimicking the way insects work together in a swarm.
The robots were developed by Marco Dorigo at the Free University of Brussels, Belgium, along with colleagues at the Institute of Cognitive Science and Technology in Italy and the Autonomous Systems Laboratory and Dalle Molle Institute for the Study of Artificial Intelligence, both in Switzerland.
See the full article & videos.
http://www.swarm-bots.org/
* NewScientist.com news service
* Tom Simonite
A "swarm" of simple-minded robots that teams up to move an object too heavy for them to manage individually has been demonstrated by robotics researchers.
The robots cannot communicate and must act only on what they can see around them. They follow simple rules to fulfil their task - mimicking the way insects work together in a swarm.
The robots were developed by Marco Dorigo at the Free University of Brussels, Belgium, along with colleagues at the Institute of Cognitive Science and Technology in Italy and the Autonomous Systems Laboratory and Dalle Molle Institute for the Study of Artificial Intelligence, both in Switzerland.
See the full article & videos.
http://www.swarm-bots.org/
Lab Meeting 20 Oct., 2006 (Jim) : Constrained Initialisation for Bearing-Only SLAM
Constrained Initialisation for Bearing-Only SLAM
Tim Bailey, ICRA2003, PDF
This paper investigates the feature initialisation problem for bearing-only SLAM. Bearing-only SLAM is an attractive capability due to its relationship with cheap vision sensing, but initialising landmarks is difficult. First, the landmark location is unconstrained by a single measurement, and second, the location estimate due to several measurements may be ill-conditioned. This paper presents a solution to the the feature initialisation problem via the method of "constrained initialisation", where measurements are stored and initialisation is deferred until sufficient constraints exist for a well-conditioned solution. A primary contribution of this paper is a measure of "well-conditioned" for initialisation within the traditional extended Kalman Filter (EKF) framework.
Tim Bailey, ICRA2003, PDF
This paper investigates the feature initialisation problem for bearing-only SLAM. Bearing-only SLAM is an attractive capability due to its relationship with cheap vision sensing, but initialising landmarks is difficult. First, the landmark location is unconstrained by a single measurement, and second, the location estimate due to several measurements may be ill-conditioned. This paper presents a solution to the the feature initialisation problem via the method of "constrained initialisation", where measurements are stored and initialisation is deferred until sufficient constraints exist for a well-conditioned solution. A primary contribution of this paper is a measure of "well-conditioned" for initialisation within the traditional extended Kalman Filter (EKF) framework.
Thursday, October 19, 2006
IEEE news: TECHNOLOGIES THAT MAKE YOU SMILE: ADDING HUMOR TO TEXT-BASED APPLICATIONS
Humor is an essential element of interpersonal communication, but surprisingly, research often neglects the topic. But according to a new article in "IEEE Intelligent Systems," computational approaches can be successfully applied to the recognition and use of verbally expressed humor. Read more (PDF).
Should we add humor to our robots? -Bob
Should we add humor to our robots? -Bob
IEEE news: Robotic surgery
Surgical robots offer a tantalizing possibility. They could allow military doctors stationed safely distant from the front line, for example, to perform operations without once putting their hands on patients. For that vision to become reality, however, surgical robots need plenty of improvement. One challenge is designing systems that can work under conditions very different from those of pristine operating rooms.
See "Doc at a Distance," by Jacob Rosen and Blake Hannaford: the link
See "Doc at a Distance," by Jacob Rosen and Blake Hannaford: the link
Wednesday, October 18, 2006
[CMU VASC seminar series] High Resolution Acquisition, Tracking and Transfer of Dynamic 3D Facial
The advent of new technologies that allow the capture of massive amounts of high resolution, high frame rate face data, leads us to propose data-driven face models that describe detailed appearance of static faces as well as to track subtle geometry changes during expressions. However, since the dense data in these 3D scans are not registered in object space, inter-frame correspondences can not be established, which makes the tracking of facial features, estimation of facial expression dynamics and other analysis difficult.
In order to use such data for the temporal study of the subtle dynamics in expressions, an efficient non-rigid 3D motion tracking algorithm is needed to establish inter-frame correspondences. In this talk, I will present two frameworks for high resolution, non-rigid dense 3D point tracking. The first framework is a hierarchical scheme using a deformable generic face model. To begin with,a generic face mesh is first deformed to fit the data at a coarse level. Then in order to capture the highly local deformations, we use a variational algorithm for non-rigid shape registration based on the integration of an implicit shape representation and the Free-Form Deformations (FFD). The second framework, a fully automatic tracking method, is presented using harmonic maps with interior feature correspondence constraints. The novelty of this work is the development of an algorithmic framework for 3D tracking that unifies tracking of intensity and geometric features, using harmonic maps with added feature correspondence constraints. Due to the strong implicit and explicit smoothness constraints imposed by both algorithms and the high-resolution data, the resulting registration/deformation field is smooth and continuous. Both our methods are validated through a series of experiments demonstrating its accuracy and efficiency.
Furthermore, the availability of high quality dynamic expression data opens a number of research directions in face modeling. In this talk, several graphics applications will be demonstrated to use the motion data to synthesize new expressions as expression transfer from a source face to a target face.
Bio:
Yang Wang received his B.S. degree and M.Sc. degree in Computer Science from Tsinghua University in 1998 and 2000 respectively. He is a Ph.D. student in the Computer Science Department at the State University of New York at Stony Brook, where he has been working with Prof. Dimitris Samaras since 2000. He specializes in illumination modeling and estimation, 3D non-rigid motion tracking and facial expression analysis and synthesis.He is a member of ACM and IEEE.
In order to use such data for the temporal study of the subtle dynamics in expressions, an efficient non-rigid 3D motion tracking algorithm is needed to establish inter-frame correspondences. In this talk, I will present two frameworks for high resolution, non-rigid dense 3D point tracking. The first framework is a hierarchical scheme using a deformable generic face model. To begin with,a generic face mesh is first deformed to fit the data at a coarse level. Then in order to capture the highly local deformations, we use a variational algorithm for non-rigid shape registration based on the integration of an implicit shape representation and the Free-Form Deformations (FFD). The second framework, a fully automatic tracking method, is presented using harmonic maps with interior feature correspondence constraints. The novelty of this work is the development of an algorithmic framework for 3D tracking that unifies tracking of intensity and geometric features, using harmonic maps with added feature correspondence constraints. Due to the strong implicit and explicit smoothness constraints imposed by both algorithms and the high-resolution data, the resulting registration/deformation field is smooth and continuous. Both our methods are validated through a series of experiments demonstrating its accuracy and efficiency.
Furthermore, the availability of high quality dynamic expression data opens a number of research directions in face modeling. In this talk, several graphics applications will be demonstrated to use the motion data to synthesize new expressions as expression transfer from a source face to a target face.
Bio:
Yang Wang received his B.S. degree and M.Sc. degree in Computer Science from Tsinghua University in 1998 and 2000 respectively. He is a Ph.D. student in the Computer Science Department at the State University of New York at Stony Brook, where he has been working with Prof. Dimitris Samaras since 2000. He specializes in illumination modeling and estimation, 3D non-rigid motion tracking and facial expression analysis and synthesis.He is a member of ACM and IEEE.
Monday, October 16, 2006
Lab Meeting 20 Oct.,2006 (Nelson) : Metric-Based Iterative Closest Point Scan Matching
Link
Javier Minguez, Luis Montesano, and Florent Lamiraux
Abstract—This paper addresses the scan matching problem
for mobile robot displacement estimation. The contribution is
a new metric distance and all the tools necessary to be used
within the iterative closest point framework. The metric
distance is defined in the configuration space of the sensor,
and takes into account both translation and rotation error of
the sensor. The new scan matching technique ameliorates
previous methods in terms of robustness, precision,
convergence, and computational load. Furthermore, it has
been extensively tested tovalidate and compare this
technique with existing methods.
Javier Minguez, Luis Montesano, and Florent Lamiraux
Abstract—This paper addresses the scan matching problem
for mobile robot displacement estimation. The contribution is
a new metric distance and all the tools necessary to be used
within the iterative closest point framework. The metric
distance is defined in the configuration space of the sensor,
and takes into account both translation and rotation error of
the sensor. The new scan matching technique ameliorates
previous methods in terms of robustness, precision,
convergence, and computational load. Furthermore, it has
been extensively tested tovalidate and compare this
technique with existing methods.
Robotics Institute Thesis Proposal: Planning with Uncertainty in Position Using High-Resolution Maps
Author:
Juan Pablo Gonzalez
Robotics Institute
Carnegie Mellon University
Abstract:
Navigating autonomously is one of the most important problems facing outdoor mobile robots. This task can be extremely difficult if no prior information is available, and would be trivial if perfect prior information existed. In practice prior maps are usually available, but their quality and resolution varies significantly.
When accurate, high-resolution prior maps are available and the position of the robot is precisely known, many existing approaches can reliably perform the navigation task for an autonomous robot. However, if the position of the robot is not precisely known, most existing approaches would fail or would have to discard the prior map and perform the much harder task of navigating without prior information.
Most outdoor robotic platforms have two ways of determining their position: a dead-reckoning system and Global Position Systems (GPS). The dead reckoning system provides a locally accurate and locally consistent estimate that drifts slowly, and the GPS provides globally accurate estimate that does not drift, but is not necessarily locally consistent. A Kalman filter usually combines these two estimates to provide an estimate that has the best of both position estimates.
While for many scenarios this combination suffices, there are many others in which GPS is not available, or its reliability is compromised by different types of interference such as mountains, buildings, foliage or jamming. In these cases, the only position estimate available is that of the dead-reckoning system which drifts with time and does not provide a position estimate accurate enough for most navigation approaches.
This proposal addresses the problem of planning with uncertainty in position using high-resolution maps. The objective is to be able to reliably navigate distances of up to one kilometer without GPS through the use of accurate, high resolution prior maps and a good dead-reckoning system. Different approaches to the problem are analyzed, depending on the types of landmarks available, the quality of the map and the quality of the perception system.
Further Details:
A copy of the thesis proposal document can be found at http://www.ri.cmu.edu/pubs/pub_5571.html.
Juan Pablo Gonzalez
Robotics Institute
Carnegie Mellon University
Abstract:
Navigating autonomously is one of the most important problems facing outdoor mobile robots. This task can be extremely difficult if no prior information is available, and would be trivial if perfect prior information existed. In practice prior maps are usually available, but their quality and resolution varies significantly.
When accurate, high-resolution prior maps are available and the position of the robot is precisely known, many existing approaches can reliably perform the navigation task for an autonomous robot. However, if the position of the robot is not precisely known, most existing approaches would fail or would have to discard the prior map and perform the much harder task of navigating without prior information.
Most outdoor robotic platforms have two ways of determining their position: a dead-reckoning system and Global Position Systems (GPS). The dead reckoning system provides a locally accurate and locally consistent estimate that drifts slowly, and the GPS provides globally accurate estimate that does not drift, but is not necessarily locally consistent. A Kalman filter usually combines these two estimates to provide an estimate that has the best of both position estimates.
While for many scenarios this combination suffices, there are many others in which GPS is not available, or its reliability is compromised by different types of interference such as mountains, buildings, foliage or jamming. In these cases, the only position estimate available is that of the dead-reckoning system which drifts with time and does not provide a position estimate accurate enough for most navigation approaches.
This proposal addresses the problem of planning with uncertainty in position using high-resolution maps. The objective is to be able to reliably navigate distances of up to one kilometer without GPS through the use of accurate, high resolution prior maps and a good dead-reckoning system. Different approaches to the problem are analyzed, depending on the types of landmarks available, the quality of the map and the quality of the perception system.
Further Details:
A copy of the thesis proposal document can be found at http://www.ri.cmu.edu/pubs/pub_5571.html.
FRC Seminar: Sliding Autonomy for Complex Coordinated Multi-Robot Tasks: Analysis & Experiments
Speaker:
Frederik Heger
Ph.D. Candidate, Robotics Institute
Abstract:
Autonomous systems are efficient but often unreliable. In domains where reliability is paramount, efficiency is sacrificed by putting an operator in control via teleoperation. We are investigating a mode of shared control called "Sliding Autonomy" that combines the efficiency of autonomy and the reliability of human control in the performance of complex tasks, such as the assembly of large structures by a team of robots. Here we introduce an approach based on Markov models that captures interdependencies between the team members and predicts system performance. We report results from a study in which three robots work cooperatively with an operator to assemble a structure. The scenario requires high precision and has a large number of failure modes. Our results support both our expectations and modeling and show that our combined robot-human team is able to perform the assembly at a level of efficiency approaching that of fully autonomous operation while increasing overall reliability to near-teleoperation levels. This increase in performance is achieved while simultaneously reducing mental operator workload.
Speaker Bio:
Frederik Heger is a third-year Ph.D. student working with Sanjiv Singh. His research interests are in enabling robots to perform complex tasks efficiently and reliably using "Sliding utonomy," and in motion planning for teams of robots working together on complex, coordinated tasks in
constrained environments.
Frederik Heger
Ph.D. Candidate, Robotics Institute
Abstract:
Autonomous systems are efficient but often unreliable. In domains where reliability is paramount, efficiency is sacrificed by putting an operator in control via teleoperation. We are investigating a mode of shared control called "Sliding Autonomy" that combines the efficiency of autonomy and the reliability of human control in the performance of complex tasks, such as the assembly of large structures by a team of robots. Here we introduce an approach based on Markov models that captures interdependencies between the team members and predicts system performance. We report results from a study in which three robots work cooperatively with an operator to assemble a structure. The scenario requires high precision and has a large number of failure modes. Our results support both our expectations and modeling and show that our combined robot-human team is able to perform the assembly at a level of efficiency approaching that of fully autonomous operation while increasing overall reliability to near-teleoperation levels. This increase in performance is achieved while simultaneously reducing mental operator workload.
Speaker Bio:
Frederik Heger is a third-year Ph.D. student working with Sanjiv Singh. His research interests are in enabling robots to perform complex tasks efficiently and reliably using "Sliding utonomy," and in motion planning for teams of robots working together on complex, coordinated tasks in
constrained environments.
Saturday, October 14, 2006
Clever cars shine at intelligent transport conference (A scanner-based car tracking system)
full article
A prototype system developed by German company Ibeo enables a car to automatically follow the vehicle ahead. At the press of a button an infrared laser scanner in the car's bumpermeasures the distance to the next vehicle and a computer maintains a safe distance, stopping and starting if it becomes stuck in traffic.

A prototype system developed by German company Ibeo enables a car to automatically follow the vehicle ahead. At the press of a button an infrared laser scanner in the car's bumpermeasures the distance to the next vehicle and a computer maintains a safe distance, stopping and starting if it becomes stuck in traffic.

The scanner can track stationary and moving objects from up to 200 metres away at speeds of up to 180 kilometres (112 miles) per hour. "It gives a very precise image of what's going on," Max Mandt-Merck of Ibeo told New Scientist.
"Our software can distinguish cars and pedestrians from the distinctive shapes the scanner detects." A video shows the information collected by the scanner (2.1MB, mov format)Airbag activation
Mandt-Merck says the scanner can also be used to warn a driver when they stray out of lane or try to overtake too close to another vehicle. It could even activate airbags 0.3 seconds before an impact, he says.
Other systems at the show aim to prevent accidents altogether, by alerting drivers when they become distracted. A video shows one that sounds an audible alarm and vibrates the driver's seat when their head turns away from the road ahead (2.75MB WMV format). "There's an infrared camera just behind the steering wheel," explains Kato Kazuya, from Japanese automotive company Aisin. "It detects the face turning by tracking its bilateral symmetry."
A video shows another system, developed by Japanese company DENSO Corporation, that uses an infrared camera to determine whether a driver is becoming drowsy (1.91MB WMV format). "It recognises the shape of your eyes and tracks the height of that shape to watch if they close," explains Takuhiro Oomi. If a driver shuts their eyes for more than a few seconds their seat vibrates and a cold draught hits their neck.
Gaze following
The same camera system could offer other functions, Oomi says. "It can also allow the headlight beams to follow your gaze, or recognise the face of a driver and adjust the seat to their saved preferences," he says.
In the car park outside the conference centre Toyota demonstrated an intelligent parking system. A video shows the system prompting a driver to identify their chosen parking spot, which is identified using ultrasonic sensors (9.8MB, WMV format).
Once the space has been selected, the wheel turns automatically and the driver needs only to limit the car's speed using the brake pedal. When reversing into a parking bay, a camera at rear of the car is used to recognise white lines on the tarmac.
The system needs 7 metres of space for parallel parking, but can fit into a regular parking bay with just 30 centimetres clearance on either side.
"Future developments will probably see a system that lets you get out and leave the car to park itself," says a Toyota spokesman. The intelligent parking system has been available on some Toyota models in Japan since November 2005 and will be available in Europe and the US from January 2007.
Predestination: Inferring Destinations from Partial Trajectories
John Krumm [Microsoft Research (Redmond, WA USA) ] and Eric Horvitz
Eighth International Conference on Ubiquitous Computing (UbiComp 2006), September 2006.
Abstract. We describe a method called Predestination that uses a history of a driver's destinations, along with data about driving behaviors, to predict where a driver is going as a trip progresses. Driving behaviors include types of destinations, driving efficiency, and trip times. Beyond considering previously visited destinations, Predestination leverages an open-world modeling methodology that considers the likelihood of users visiting previously unobserved locations based on trends in the data and on the background properties of locations. This allows our algorithm to smoothly transition between "out of the box" with no training data to more fully trained with increasing numbers of observations. Multiple components of the analysis are fused via Bayesian inference to pro-duce a probabilistic map of destinations. Our algorithm was trained and tested on hold-out data drawn from a database of GPS driving data gathered from 169 different subjects who drove 7,335 different trips.
[Full]
[Homepage]
Eighth International Conference on Ubiquitous Computing (UbiComp 2006), September 2006.
Abstract. We describe a method called Predestination that uses a history of a driver's destinations, along with data about driving behaviors, to predict where a driver is going as a trip progresses. Driving behaviors include types of destinations, driving efficiency, and trip times. Beyond considering previously visited destinations, Predestination leverages an open-world modeling methodology that considers the likelihood of users visiting previously unobserved locations based on trends in the data and on the background properties of locations. This allows our algorithm to smoothly transition between "out of the box" with no training data to more fully trained with increasing numbers of observations. Multiple components of the analysis are fused via Bayesian inference to pro-duce a probabilistic map of destinations. Our algorithm was trained and tested on hold-out data drawn from a database of GPS driving data gathered from 169 different subjects who drove 7,335 different trips.
[Full]
[Homepage]
Thursday, October 12, 2006
Lab meeitng 13 Oct., 2006 (Yu-Chun)
1. Fostering Common Ground in Human-Robot Interaction
IEEE International Workshop on Robots and Human Interactive Communication
Sara Kiesler
Abstract:
Effective communication between people and interactive robots will benefit if they have a common ground of understanding. I discuss how the common ground principle of least collective effort can be used to predict and design human robot interactions. Social cues lead people to create a mental model of a robot and estimates of its knowledge. People’s mental model and knowledge estimate will, in turn, influence the effort they expend to communicate with the robot. People will explain their message in less detail to a knowledgeable robot with which they have more common ground. This process can be leveraged to design interactions that have an appropriate style of robot direction and that accommodate to differences among people.
Link
2. Interactions with a Moody Robot
Proceedings of Human-Robot Interaction, 2006
Rachel Gockley, Jodi Forlizzi, Reid Simmons
Abstract:
This paper reports on the results of a long-term experiment in which a social robot’s facial expressions were changed to reflect different moods. While the facial changes in each condition were not extremely different, they still altered how people interacted with the robot. On days when many visitors were present, average interactions with the robot were longer when the robot displayed either a “happy” or a “sad” expression instead of a neutral face, but the opposite was true for low-visitor days. The implications of these findings for human-robot social interaction are discussed.
Link
IEEE International Workshop on Robots and Human Interactive Communication
Sara Kiesler
Abstract:
Effective communication between people and interactive robots will benefit if they have a common ground of understanding. I discuss how the common ground principle of least collective effort can be used to predict and design human robot interactions. Social cues lead people to create a mental model of a robot and estimates of its knowledge. People’s mental model and knowledge estimate will, in turn, influence the effort they expend to communicate with the robot. People will explain their message in less detail to a knowledgeable robot with which they have more common ground. This process can be leveraged to design interactions that have an appropriate style of robot direction and that accommodate to differences among people.
Link
2. Interactions with a Moody Robot
Proceedings of Human-Robot Interaction, 2006
Rachel Gockley, Jodi Forlizzi, Reid Simmons
Abstract:
This paper reports on the results of a long-term experiment in which a social robot’s facial expressions were changed to reflect different moods. While the facial changes in each condition were not extremely different, they still altered how people interacted with the robot. On days when many visitors were present, average interactions with the robot were longer when the robot displayed either a “happy” or a “sad” expression instead of a neutral face, but the opposite was true for low-visitor days. The implications of these findings for human-robot social interaction are discussed.
Link
News:Device helps navigate daily life

By CNN
POSTED: 1423 GMT (2223 HKT), October 10, 2006
ATLANTA, Georgia (AP) -- Satellite-based navigation gadgets can guide motorists from high above, saving bumbling drivers countless hours and extra trips to the gas station. But directing people on a much smaller scale -- such as inside an office -- is a much greater challenge.
Locator equipment based on Global Positioning System satellites is accurate to about 10 feet -- fine for drivers searching for the next right turn but not for pedestrians seeking a front door. And the range of GPS is limited indoors, and it can't on its own differentiate between a path and a wall.
Georgia Institute of Technology researchers are trying to pick up where GPS leaves off. Its System for Wearable Audio Navigation, or SWAN, consists of a wearable computer connected to a headband packed with sensors that help sight-impaired users know where they are and how to get where they're going.
Besides a pendant-sized wireless GPS tracker, there are light sensors and thermometers that help distinguish between indoors and outdoors. Cameras gauge how far away objects and obstacles are. A compass establishes direction. And an inertia detector tracks the roll, pitch and yaw of the user's head.
All the data are crunched by a computer in a backpack, which relays high-pitch sonar-like signals that direct users to their destinations. It also works with a database of maps and floor plans to help pinpoint each sidewalk, door, hall and stairwell.
[The full]
[Robotics Institute Seminar, October 13, 2006]Object Classification, Recognition and Segmentation by a Hierarchy of Abstract Fragments
Shimon Ullman
Ruth and Samy Cohn Professor of Computer Science
Weizmann Institute of Science
Time and Place
Mauldin Auditorium (NSH 1305)Refreshments 3:15 pmTalk 3:30 pm
Abstract
I will describe an approach to object recognition which combines general classification, individual recognition, and figure-ground segmentation. The approach is based on representing shapes within a class by a hierarchy of shared sub-structures called fragments, selected by maximizing the information delivered for classification. For the task of individual recognition, these fragments are generalized to become abstract fragments, representing the same object part under different viewing conditions. The resulting feature hierarchy is used to recognize new images by the application of a feed-forward sweep from low to high levels of the hierarchy, followed by a sweep from the high to low levels. Finally, image segmentation into an object and background is combined in this approach with the recognition process. Some relations to the human visual system will be briefly discussed.
Speaker Biography
Shimon Ullman is the Ruth and Samy Cohn Professor of Computer Science in the department of computer science and applied mathematics at the Weizmann Institute of Science in Israel. He received his Bs.C. from the Hebrew University in Jerusalem, and Ph.D. from M.I.T, where he has been a Professor in the Brain and Cognitive Science Department and in the Artificial Intelligence Laboratory. His main areas of research are human and computer vision, cognition, and brain modeling.
Speaker Appointments
For appointments, please contact Janice Brochetti (janiceb@cs.cmu.edu)
Ruth and Samy Cohn Professor of Computer Science
Weizmann Institute of Science
Time and Place
Mauldin Auditorium (NSH 1305)Refreshments 3:15 pmTalk 3:30 pm
Abstract
I will describe an approach to object recognition which combines general classification, individual recognition, and figure-ground segmentation. The approach is based on representing shapes within a class by a hierarchy of shared sub-structures called fragments, selected by maximizing the information delivered for classification. For the task of individual recognition, these fragments are generalized to become abstract fragments, representing the same object part under different viewing conditions. The resulting feature hierarchy is used to recognize new images by the application of a feed-forward sweep from low to high levels of the hierarchy, followed by a sweep from the high to low levels. Finally, image segmentation into an object and background is combined in this approach with the recognition process. Some relations to the human visual system will be briefly discussed.
Speaker Biography
Shimon Ullman is the Ruth and Samy Cohn Professor of Computer Science in the department of computer science and applied mathematics at the Weizmann Institute of Science in Israel. He received his Bs.C. from the Hebrew University in Jerusalem, and Ph.D. from M.I.T, where he has been a Professor in the Brain and Cognitive Science Department and in the Artificial Intelligence Laboratory. His main areas of research are human and computer vision, cognition, and brain modeling.
Speaker Appointments
For appointments, please contact Janice Brochetti (janiceb@cs.cmu.edu)
Wednesday, October 11, 2006
Lab meeitng 13 Oct., 2006 (Casey): Boosting with Prior Knowledge for Call Classification
Title: Boosting with Prior Knowledge for Call Classification (IEEE Transactions on Speech and Audio Processing 2005)
Authors: Robert E. Schapire, Marie Rochery, Mazin Rahim and Narendra Gupta
Abstract:
The use of boosting for call classification in spoken language
understanding is described in this paper. An extension to the
AdaBoost algorithm is presented that permits the incorporation
of prior knowledge of the application as a means of compensating
for the large dependence on training data. We give a convergence
result for the algorithm, and we describe experiments on
four datasets showing that prior knowledge can substantially improve
classification performance.
[Paper Download]
I will also introduce discreteAdaboost, realAdaboost, floatAdaboost etc.
Authors: Robert E. Schapire, Marie Rochery, Mazin Rahim and Narendra Gupta
Abstract:
The use of boosting for call classification in spoken language
understanding is described in this paper. An extension to the
AdaBoost algorithm is presented that permits the incorporation
of prior knowledge of the application as a means of compensating
for the large dependence on training data. We give a convergence
result for the algorithm, and we describe experiments on
four datasets showing that prior knowledge can substantially improve
classification performance.
[Paper Download]
I will also introduce discreteAdaboost, realAdaboost, floatAdaboost etc.
Tuesday, October 10, 2006
Lab meeitng 13 Oct., 2006 (Any): Outdoor SLAM using Visual Appearance and Laser Ranging
Title: Outdoor SLAM using Visual Appearance and Laser Ranging, ICRA'06 Best Paper Award
Author: Paul Newman, David Cole and Kin Ho, Oxford University Robotics Research Group
[Link] [Local Copy]
Abstract:
Author: Paul Newman, David Cole and Kin Ho, Oxford University Robotics Research Group
[Link] [Local Copy]
Abstract:
This paper describes a 3D SLAM system using information from an actuated laser scanner and camera installed on a mobile robot.The laser samples the local geometry of the environment and is used to incrementally build a 3D point-cloud map of the workspace. Sequences of images from the camera are used to detect loop closure events (without reference to the internal estimates of vehicle location) using a novel appearancebased retrieval system. The loop closure detection is robust to repetitive visual structure and provides a probabilistic measure of confidence. The images suggesting loop closure are then further processed with their corresponding local laser scans to yield putative Euclidean image-image transformations. We show how naive application of this transformation to effect the loop closure can lead to catastrophic linearization errors and go on to describe a way in which gross, pre-loop closing errors can be successfully annulled. We demonstrate our system working in a challenging, outdoor setting containing substantial loops and beguiling, gently curving traversals. The results are overlaid on an aerial image to provide a ground truth comparison with the estimated map. The paper concludes with an extension into the multi-robot domain in which 3D maps resulting from distinct SLAM sessions (no common reference frame) are combined without recourse to mutual observation.
CMU VASC talk: Joint Image Alignment--What's it Good For?
Erik Learned Miller, UMass, Amherst
Monday, Oct 9, 3:30pm, NSH 1507
In this talk, I will start by reviewing previous work on "congealing", a joint alignment algorithm for images that uses a minimum entropy criterion. I show how congealing can be used not only to align images which have undergone certain sets of transformations, but how it can be used to eliminate a variety of different types of unwanted "distortion" in images, such as the bias fields seen in magnetic resonance imaging. I show how any that produces a scalar score can be turned into a congealing algorithm. I will also discuss recent applications to new problems, including the role of congealing in our object detection algorithmhyper-feature face recognizer, and a project to automatically define the most salient points for registration in medical image volumes.
Monday, Oct 9, 3:30pm, NSH 1507
In this talk, I will start by reviewing previous work on "congealing", a joint alignment algorithm for images that uses a minimum entropy criterion. I show how congealing can be used not only to align images which have undergone certain sets of transformations, but how it can be used to eliminate a variety of different types of unwanted "distortion" in images, such as the bias fields seen in magnetic resonance imaging. I show how any that produces a scalar score can be turned into a congealing algorithm. I will also discuss recent applications to new problems, including the role of congealing in our object detection algorithmhyper-feature face recognizer, and a project to automatically define the most salient points for registration in medical image volumes.
IEEE ITSS Newsletter vol 8 nr 3, September 2006
The new issue of the IEEE ITSS (Intelligent Transportation Systems Society) Newsletter (Vol.8, Nr.3, September 2006) is available for download.
In this issue you will find a lot of interesting material:
- ITSS related news; in particular many new initiatives from the ITS Society
- technical papers
- conference reports and announcements
- research overview focusing on EU projects on cooperative road-vehicle systems
You can find the ITSS Newsletter at the IEEE ITSS official web site address:
http://www.ewh.ieee.org/tc/its/
or directly at:
http://www.its.washington.edu/itsc/v8n3.pdf
In this issue you will find a lot of interesting material:
- ITSS related news; in particular many new initiatives from the ITS Society
- technical papers
- conference reports and announcements
- research overview focusing on EU projects on cooperative road-vehicle systems
You can find the ITSS Newsletter at the IEEE ITSS official web site address:
http://www.ewh.ieee.org/tc/its/
or directly at:
http://www.its.washington.edu/itsc/v8n3.pdf
CMU Intelligent Seminar: Decoding conscious and unconscious mental states from brain activity in humans
John-Dylan Haynes
Max-Planck Institute CNS, Leipzig, Germany
Faculty Host: Tom Mitchell
Recent advances in human neuroimaging have shown that it is possible to accurately decode a person's conscious experience based only on non-invasive multivariate measurements of their brain activity. Such 'brain reading' has mostly been studied in the domain of visual perception, where it helps reveal the way in which individual experiences are encoded in the human brain. Here several studies will be presented that directly address the relationship between neural encoding of information (as measured with fMRI) and its availability for awareness. These studies include comparisons of neural and perceptual information, unconscious information processing, decoding of timecourses of perception, as well as decoding of high-level mental states related to the control of attention and action. A number of fundamental challenges to the science of "brain reading" will be presented and discussed.
Max-Planck Institute CNS, Leipzig, Germany
Faculty Host: Tom Mitchell
Recent advances in human neuroimaging have shown that it is possible to accurately decode a person's conscious experience based only on non-invasive multivariate measurements of their brain activity. Such 'brain reading' has mostly been studied in the domain of visual perception, where it helps reveal the way in which individual experiences are encoded in the human brain. Here several studies will be presented that directly address the relationship between neural encoding of information (as measured with fMRI) and its availability for awareness. These studies include comparisons of neural and perceptual information, unconscious information processing, decoding of timecourses of perception, as well as decoding of high-level mental states related to the control of attention and action. A number of fundamental challenges to the science of "brain reading" will be presented and discussed.
Thursday, October 05, 2006
Metric-Based Iterative Closest Point Scan Matching
IEEE TRANSACTIONS ON ROBOTICS,
VOL. 22, NO. 5, OCTOBER 2006
Metric-Based Iterative Closest Point Scan Matching
Javier Minguez, Luis Montesano, and Florent Lamiraux
Abstract—This paper addresses the scan matching problem
for mobile robot displacement estimation. The contribution
is a new metric distance and all the tools necessary to be used
within the iterative closest point framework.
The metric distance is defined in the configuration space of the
sensor, and takes into account both translation and rotation
error of the sensor. The new scan matching technique
ameliorates previous methods in terms of robustness, precision,
convergence, and computational load. Furthermore, it has been
extensively tested to validate and compare this technique with
existing methods.
VOL. 22, NO. 5, OCTOBER 2006
Metric-Based Iterative Closest Point Scan Matching
Javier Minguez, Luis Montesano, and Florent Lamiraux
Abstract—This paper addresses the scan matching problem
for mobile robot displacement estimation. The contribution
is a new metric distance and all the tools necessary to be used
within the iterative closest point framework.
The metric distance is defined in the configuration space of the
sensor, and takes into account both translation and rotation
error of the sensor. The new scan matching technique
ameliorates previous methods in terms of robustness, precision,
convergence, and computational load. Furthermore, it has been
extensively tested to validate and compare this technique with
existing methods.
Wednesday, October 04, 2006
Special FRC Seminar noon, Wednesday, October 4 - A High Speed Lidar Video Camera
Title: A High Speed Lidar Video Camera
Speakers: Dr. Dirk Langer and Dr. Jim O'Neill
Date: Wednesday, October 4, 2006
Time: Noon
Location: NSH 1109
Abstract:
Accurately capturing the geometry of an environment or distinct objects
within that environment is an important task for many fields of industrial
automation, security and military applications. The classical computer
vision approach uses passive techniques such as stereovision, photogrammetry
or motion stereo. However, those techniques are not yet sufficiently
reliable or fast enough to be used in many applications, most notably
real-time systems. Active sensors, which generate the illumination
themselves instead of using only the ambient light, are a viable alternative
to passive sensors. These sensors feature direct access to corresponding
range and visual image information in real-time.
In this presentation, we will introduce our new Lidar Video Camera, which is
a joint development between Z+F USA, Inc. and Autonosys, Inc.. This product
is based on the well known Z+F laser range finder in conjunction with a
planar-polygonal dual mirror. The unique feature of this scanner is its very
high frame rate of 5 Hz at 256 x 144 pixel resolution and 1 Hz at 512 x 288
pixel resolution, coupled with a high range and intensity resolution of
16-bit and mm accuracy. The current unit has a maximum range of 53 metres,
which can be expanded to 80 metres.
Speaker Bio:
Dr. Dirk Langer has been involved with Laser Scanning Technology and related
hardware and software solutions for the last 10 years. Since 1998 he has
been responsible for the US operations of Z+F, an internationally known
company in this area. He has a Dipl.-Ing. degree in Electrical Engineering
from the Technical University Munich in Germany and a PhD in Robotics from
Carnegie Mellon University in Pittsburgh, PA.
Before joining Z+F in 1998, he held research positions at the Robotics
Institute at Carnegie Mellon University and was involved in a variety of
projects ranging from autonomous vehicle navigation to the development of
radar and laser imaging systems.
Dr. Jim O'Neill is the CEO of AutonoSys Inc, a startup company specializing
in systems and sensors for autonomous vehicles. AutonoSys Inc was the only
non-US based qualifier for the 2005 Darpa Grand Challenge NQE.
Prior to founding AutonoSys, Jim O'Neill gained over twenty-five years of
business and technical experience in a variety of high tech industries. His
last position before AutonoSys was at JDSU, a Fortune 500 company in the
telecom industry. At JDSU, Dr O'Neill was head of business units in the US
and Canada with combined sales of approximately US$40M.
Dr O'Neill's formal education includes a doctoral degree in Astrophysics
from Oxford University in the UK.
Speakers: Dr. Dirk Langer and Dr. Jim O'Neill
Date: Wednesday, October 4, 2006
Time: Noon
Location: NSH 1109
Abstract:
Accurately capturing the geometry of an environment or distinct objects
within that environment is an important task for many fields of industrial
automation, security and military applications. The classical computer
vision approach uses passive techniques such as stereovision, photogrammetry
or motion stereo. However, those techniques are not yet sufficiently
reliable or fast enough to be used in many applications, most notably
real-time systems. Active sensors, which generate the illumination
themselves instead of using only the ambient light, are a viable alternative
to passive sensors. These sensors feature direct access to corresponding
range and visual image information in real-time.
In this presentation, we will introduce our new Lidar Video Camera, which is
a joint development between Z+F USA, Inc. and Autonosys, Inc.. This product
is based on the well known Z+F laser range finder in conjunction with a
planar-polygonal dual mirror. The unique feature of this scanner is its very
high frame rate of 5 Hz at 256 x 144 pixel resolution and 1 Hz at 512 x 288
pixel resolution, coupled with a high range and intensity resolution of
16-bit and mm accuracy. The current unit has a maximum range of 53 metres,
which can be expanded to 80 metres.
Speaker Bio:
Dr. Dirk Langer has been involved with Laser Scanning Technology and related
hardware and software solutions for the last 10 years. Since 1998 he has
been responsible for the US operations of Z+F, an internationally known
company in this area. He has a Dipl.-Ing. degree in Electrical Engineering
from the Technical University Munich in Germany and a PhD in Robotics from
Carnegie Mellon University in Pittsburgh, PA.
Before joining Z+F in 1998, he held research positions at the Robotics
Institute at Carnegie Mellon University and was involved in a variety of
projects ranging from autonomous vehicle navigation to the development of
radar and laser imaging systems.
Dr. Jim O'Neill is the CEO of AutonoSys Inc, a startup company specializing
in systems and sensors for autonomous vehicles. AutonoSys Inc was the only
non-US based qualifier for the 2005 Darpa Grand Challenge NQE.
Prior to founding AutonoSys, Jim O'Neill gained over twenty-five years of
business and technical experience in a variety of high tech industries. His
last position before AutonoSys was at JDSU, a Fortune 500 company in the
telecom industry. At JDSU, Dr O'Neill was head of business units in the US
and Canada with combined sales of approximately US$40M.
Dr O'Neill's formal education includes a doctoral degree in Astrophysics
from Oxford University in the UK.
News: Musical robot composes, performs and teaches
 By Matthew Abshire
By Matthew AbshireCNN
ATLANTA, Georgia (CNN) -- A professor of musical technology at Georgia Tech, Gil Weinberg, enlisted the support of graduate student Scott Driscoll to create Haile -- the first truly robotic musician. In this way, he became a sort of Geppetto creating his musical Pinocchio.
"Computers have been playing music for 50 years," Driscoll said. "But we wanted to create something that didn't just play back what it heard, but play off it, too."
Think of Haile (pronounced Hi-lee) as a robotic partner in the percussion form of dueling banjos. Although it has numerous musical algorithms programmed into it, Haile's basic function is to "listen" to what musicians are playing and play along with them.
[See the full article]
Tuesday, October 03, 2006
Researchers unveil emotive, interactive robot: "Quasi"
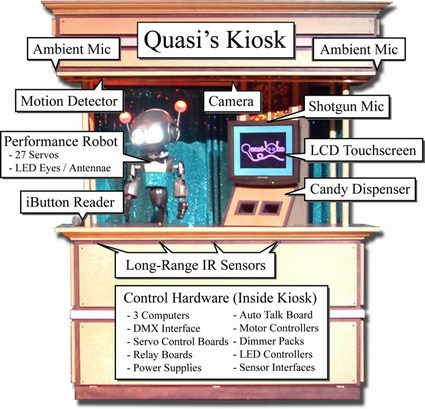
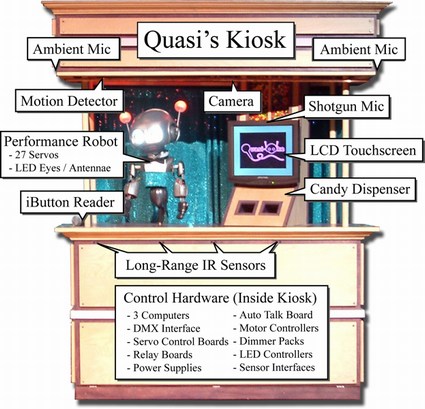{kind=link}
We've already got robotic eyedrops that can facilitate conversation and react accordingly to their surroundings, and there's even an R2-D2 clone to get your feet shuffling once you've recovered, but researchers at Carnegie Mellon University have developed an emotive robot, complete with his own interactive booth, that can express its feelings through body language. Quasi, a member of the Interbots Platform, resides in a booth full of gizmos that allow him to see, hear, and feel the outside world; sporting a touchscreen LCD, long-range IR sensors, motion detector, webcam, microphones, and even a candy dispenser, humans have a myriad of choices when it comes to breaking the ice with the "animatronic figure." To get his reactions in gear, 27 Hitec servo motors are used to control the motions of his eyelids and telescoping antenna, while a bevy of LED lighting fixtures illuminate to convey his swinging moods and personality without so much as a clang from his aluminum lips. The team is planning on adding speech capability and a more mechanical armature in the near future, after which he'll probably be the self-nominated leader of the soon-to-be-uncontrollable Swarmanoid clan.
link
video (Quasi the Robot @ Wired NextFest 2006)
video (Quasi the Robot on Dicovery Channel)
News: DARPA chooses teams for next robot race
The winners of last year's Pentagon-sponsored robot race are back to take on another challenge - this time to develop a vehicle that can drive through congested city traffic all by itself.
Stanford University, whose unmanned Volkswagen dubbed Stanley won last year's desert race, was among 11 teams selected Monday to receive government money to participate in a contest requiring robots to carry out a simulated military supply mission.
See the full article
Stanford University, whose unmanned Volkswagen dubbed Stanley won last year's desert race, was among 11 teams selected Monday to receive government money to participate in a contest requiring robots to carry out a simulated military supply mission.
See the full article
Monday, October 02, 2006
New Scientist News: INVENTION: Invisible drones
Can a surveillance drone be made virtually invisible? A US company thinks so, and their patent application explains how.
"Persistence of vision" turns the fast-moving rotors of any helicopter into a near-transparent blur, while the slow-moving body looks solid. So why not make the entire aircraft spin as it flies, turning it into a single faint blur in the sky?
Find out more, and view the design drawings and a demonstration video, here: the link
"Persistence of vision" turns the fast-moving rotors of any helicopter into a near-transparent blur, while the slow-moving body looks solid. So why not make the entire aircraft spin as it flies, turning it into a single faint blur in the sky?
Find out more, and view the design drawings and a demonstration video, here: the link
CMU VASC seminar : Probabilistic Models for Image Parsing
Title : Probabilistic Models for Image Parsing
Speaker : Xiaofeng Ren (TTI Chicago)
Abstract:
A grand challenge of computer vision is to understand and parse natural
images into boundaries, surfaces and objects. To solve this problem we
would inevitably need to work with visual entities and cues of
heterogeneous nature, such as brightness and texture at low-level, contour
and region grouping at mid-level, and shape recognition at high-level.
Learning to represent and incorporate these entities and cues, along with
the complexity of the visual world itself, calls for probabilistic models
for image parsing. Many previous efforts in this line suffer from issues
such as lack of a compact representation, lack of scale invariance or lack
of comprehensive experimentation. We describe a scale-invariant image
representation using piecewise linear approximations of contours and the
constrained Delaunay triangulation (CDT) for completing relentless gaps.
On top of the CDT graph we develop conditional random fields (CRF) for
contour completion, figure/ground organization as well as object
segmentation. Large datasets of human-annotated natural images are
utilized for both training and evaluation. Our quantitative results are
the first to demonstrate the working of mid-level visual cues in general
natural scenes. The CDT/CRF framework enables efficient representation and
inference of both bottom-up and top-down information, hence applicable to
various vision problems. We extend our work to joint object recognition
and segmentation, in particular finding people, in static images and
video.
Bio:
Xiaofeng Ren received his B.S. in computer science from Zhejiang
University, China, and his M.S. from Stanford University. In 2006 he
received his Ph.D. degree in computer science from University of
California at Berkeley, under the supervision of Jitendra Malik. He is
currently a research assistant professor at Toyota Technological Institute
at Chicago. His research interests lie broadly in the areas of computer
vision and artificial intelligence, and he has mainly worked on contour
completion, image segmentation, figure/ground labeling and human body pose
recovery.
Speaker's homepage : http://www.cs.berkeley.edu/~xren/
Appointments: Email Janice Brochetti
Origin : http://vasc.ri.cmu.edu/seminar/
Speaker : Xiaofeng Ren (TTI Chicago)
Abstract:
A grand challenge of computer vision is to understand and parse natural
images into boundaries, surfaces and objects. To solve this problem we
would inevitably need to work with visual entities and cues of
heterogeneous nature, such as brightness and texture at low-level, contour
and region grouping at mid-level, and shape recognition at high-level.
Learning to represent and incorporate these entities and cues, along with
the complexity of the visual world itself, calls for probabilistic models
for image parsing. Many previous efforts in this line suffer from issues
such as lack of a compact representation, lack of scale invariance or lack
of comprehensive experimentation. We describe a scale-invariant image
representation using piecewise linear approximations of contours and the
constrained Delaunay triangulation (CDT) for completing relentless gaps.
On top of the CDT graph we develop conditional random fields (CRF) for
contour completion, figure/ground organization as well as object
segmentation. Large datasets of human-annotated natural images are
utilized for both training and evaluation. Our quantitative results are
the first to demonstrate the working of mid-level visual cues in general
natural scenes. The CDT/CRF framework enables efficient representation and
inference of both bottom-up and top-down information, hence applicable to
various vision problems. We extend our work to joint object recognition
and segmentation, in particular finding people, in static images and
video.
Bio:
Xiaofeng Ren received his B.S. in computer science from Zhejiang
University, China, and his M.S. from Stanford University. In 2006 he
received his Ph.D. degree in computer science from University of
California at Berkeley, under the supervision of Jitendra Malik. He is
currently a research assistant professor at Toyota Technological Institute
at Chicago. His research interests lie broadly in the areas of computer
vision and artificial intelligence, and he has mainly worked on contour
completion, image segmentation, figure/ground labeling and human body pose
recovery.
Speaker's homepage : http://www.cs.berkeley.edu/~xren/
Appointments: Email Janice Brochetti
Origin : http://vasc.ri.cmu.edu/seminar/
Sunday, October 01, 2006
[ML Lunch] Monday 10/02
Hi,
We'll be having a KDD 2006 conference review
session this Monday 10/02.
Hanghang Tong and Jimeng Sun will lead the
session with the following
papers:
1. Hanghang Tong on
Center-Piece Subgraphs: Problem Definition and
Fast Solutions.
by Hanghang Tong and Christos Faloutsos
2. Jimeng Sun on
Beyond Streams and Graphs: Dynamic Tensor
Analysis.
by Jimeng Sun, Yufei Tao, Christos Faloutsos
Venue: NSH 1507
Date : Monday, October 02
Time : 12:00 noon
And of course, thanks to MLD, lunch will be
served.
For schedules, links to papers et al, please see
the web page:
http://www.cs.cmu.edu/~learning
We are on the lookout for speakers for the
semester, so do send any of
us an email if you'd like to give a talk.
Your ML Lunch organizing committee,
Edoardo Airoldi (eairoldi@cs.cmu.edu)
Anna Goldenberg (anya@cs.cmu.edu)
Leonid Kontorovich (lkontor@cs.cmu.edu)
Andreas Krause (krausea@cs.cmu.edu)
Jure Leskovec (jure@cs.cmu.edu)
Pradeep Ravikumar (pradeepr@cs.cmu.edu)
=======================================================================
Abstracts:
1. Center-Piece Subgraphs: Problem Definition and
Fast Solutions
by Hanghang Tong and Christos Faloutsos
Given $\QN$ nodes in a social network (say,
authorship network), how can
we find the node/author that is the center-piece,
and has direct or
indirect connections to all, or most of them? For
example, this node
could be the common advisor, or someone who
started the research area
that the $\QN$ nodes belong to. Isomorphic
scenarios appear in law
enforcement (find the master-mind criminal,
connected to all current
suspects), gene regulatory networks (find the
protein that participates
in pathways with all or most of the given $\QN$
proteins), viral
marketing and many more. Connection subgraphs is
an important first
step, handling the case of $\QN$=2 query nodes.
Then, the connection
subgraph algorithm finds the $b$ intermediate
nodes, that provide a good
connection between the two query nodes. Here we
generalize the challenge
in multiple dimensions: First, we allow more than
two query nodes.
Second, we allow a whole family of queries,
ranging from 'OR' to 'AND',
with 'softAND' in-between. Finally, we design and
compare a fast
approximation, and study the quality/speed
trade-off. We also present
experiments on the DBLP dataset. The experiments
confirm that our
proposed method naturally deals with multi-source
queries and that the
resulting subgraphs agree with our intuition.
Wall-clock timing results
on the DBLP dataset show that our proposed
approximation achieve good
accuracy for about $6:1$ speedup.
2. Beyond Streams and Graphs: Dynamic Tensor
Analysis
by Jimeng Sun, Yufei Tao, Christos Faloutsos
How do we find patterns in author-keyword
associations, evolving over
time? Or in DataCubes, with
product-branch-customer sales information?
Matrix decompositions, like principal component
analysis (PCA) and
variants, are invaluable tools for mining,
dimensionality reduction,
feature selection, rule identification in
numerous settings like
streaming data, text, graphs, social networks and
many more.However,
they have only two orders, like author and
keyword, in the above
example. We propose to envision such higher order
data as tensors, and
tap the vast literature on the topic. However,
these methods do not
necessarily scale up, let alone operate on
semi-infinite streams. Thus,
we introduce the dynamic tensor analysis (DTA)
method, and its variants.
DTA provides a compact summary for high-order and
high-dimensional data,
and it also reveals the hidden correlations.
Algorithmically,we designed
DTA very carefully so that it is (a) scalable,
(b) space efficient (it
does not need to store the past) and (c) fully
automatic with no need
for user defined parameters. Moreover, we propose
STA, a streaming
tensor analysis method, which provides a fast,
streaming approximation
to DTA. We implemented all our methods, and
applied them in two real
settings, namely, anomaly detection and multi-way
latent semantic
indexing. We used two real, large datasets, one
on network flow data
(100GB over 1 month) and one from DBLP (200MB
over 25 years). Our
experiments show that our methods are fast,
accurate and that they find
interesting patterns and outliers on the real
datasets.
We'll be having a KDD 2006 conference review
session this Monday 10/02.
Hanghang Tong and Jimeng Sun will lead the
session with the following
papers:
1. Hanghang Tong on
Center-Piece Subgraphs: Problem Definition and
Fast Solutions.
by Hanghang Tong and Christos Faloutsos
2. Jimeng Sun on
Beyond Streams and Graphs: Dynamic Tensor
Analysis.
by Jimeng Sun, Yufei Tao, Christos Faloutsos
Venue: NSH 1507
Date : Monday, October 02
Time : 12:00 noon
And of course, thanks to MLD, lunch will be
served.
For schedules, links to papers et al, please see
the web page:
http://www.cs.cmu.edu/~learning
We are on the lookout for speakers for the
semester, so do send any of
us an email if you'd like to give a talk.
Your ML Lunch organizing committee,
Edoardo Airoldi (eairoldi@cs.cmu.edu)
Anna Goldenberg (anya@cs.cmu.edu)
Leonid Kontorovich (lkontor@cs.cmu.edu)
Andreas Krause (krausea@cs.cmu.edu)
Jure Leskovec (jure@cs.cmu.edu)
Pradeep Ravikumar (pradeepr@cs.cmu.edu)
=======================================================================
Abstracts:
1. Center-Piece Subgraphs: Problem Definition and
Fast Solutions
by Hanghang Tong and Christos Faloutsos
Given $\QN$ nodes in a social network (say,
authorship network), how can
we find the node/author that is the center-piece,
and has direct or
indirect connections to all, or most of them? For
example, this node
could be the common advisor, or someone who
started the research area
that the $\QN$ nodes belong to. Isomorphic
scenarios appear in law
enforcement (find the master-mind criminal,
connected to all current
suspects), gene regulatory networks (find the
protein that participates
in pathways with all or most of the given $\QN$
proteins), viral
marketing and many more. Connection subgraphs is
an important first
step, handling the case of $\QN$=2 query nodes.
Then, the connection
subgraph algorithm finds the $b$ intermediate
nodes, that provide a good
connection between the two query nodes. Here we
generalize the challenge
in multiple dimensions: First, we allow more than
two query nodes.
Second, we allow a whole family of queries,
ranging from 'OR' to 'AND',
with 'softAND' in-between. Finally, we design and
compare a fast
approximation, and study the quality/speed
trade-off. We also present
experiments on the DBLP dataset. The experiments
confirm that our
proposed method naturally deals with multi-source
queries and that the
resulting subgraphs agree with our intuition.
Wall-clock timing results
on the DBLP dataset show that our proposed
approximation achieve good
accuracy for about $6:1$ speedup.
2. Beyond Streams and Graphs: Dynamic Tensor
Analysis
by Jimeng Sun, Yufei Tao, Christos Faloutsos
How do we find patterns in author-keyword
associations, evolving over
time? Or in DataCubes, with
product-branch-customer sales information?
Matrix decompositions, like principal component
analysis (PCA) and
variants, are invaluable tools for mining,
dimensionality reduction,
feature selection, rule identification in
numerous settings like
streaming data, text, graphs, social networks and
many more.However,
they have only two orders, like author and
keyword, in the above
example. We propose to envision such higher order
data as tensors, and
tap the vast literature on the topic. However,
these methods do not
necessarily scale up, let alone operate on
semi-infinite streams. Thus,
we introduce the dynamic tensor analysis (DTA)
method, and its variants.
DTA provides a compact summary for high-order and
high-dimensional data,
and it also reveals the hidden correlations.
Algorithmically,we designed
DTA very carefully so that it is (a) scalable,
(b) space efficient (it
does not need to store the past) and (c) fully
automatic with no need
for user defined parameters. Moreover, we propose
STA, a streaming
tensor analysis method, which provides a fast,
streaming approximation
to DTA. We implemented all our methods, and
applied them in two real
settings, namely, anomaly detection and multi-way
latent semantic
indexing. We used two real, large datasets, one
on network flow data
(100GB over 1 month) and one from DBLP (200MB
over 25 years). Our
experiments show that our methods are fast,
accurate and that they find
interesting patterns and outliers on the real
datasets.
Subscribe to:
Posts (Atom)